Deploy Models To Production
Modela can deploy Model resources as native Kubernetes Deployments once they have moved past the Packaging phase through being selected by their parent Study or by manually marking the model for testing. The Predictor resource manages the creation of the Deployment and initializes a prediction server with the model’s weights. You can automatically create a Predictor by selecting Release on a completed Model, or create one manually by navigating to the Predictors tab on the Data Product sidebar.
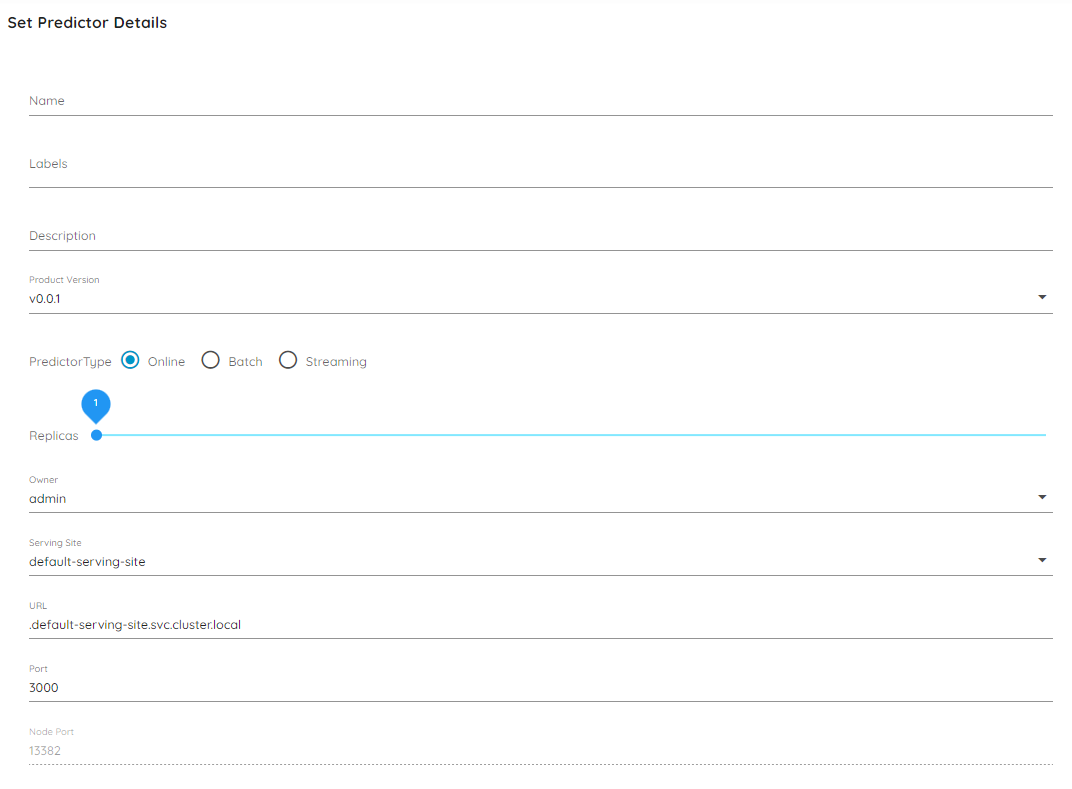
Access Method
After filling out the metadata fields, you can define how the Predictor service is exposed based on a native Kubernetes ServiceType. Based on this access type, your service will be accessible in the following way:
| Access Method | Description |
|---|---|
| ClusterIP | The service is exposed on a cluster-internal virtual IP at the port specified by Port and can only be accessed inside the cluster. Applications running inside the cluster can resolve the service using the DNS name specified by the URL field of your Predictor, or you can port-forward the prediction proxy for external access using Kubectl (e.g. kubectl port-forward -n default-serving-site svc/my-predictor-name 3000:3000) |
| NodePort | The service is accessible from the IP of any node on your cluster at the port specified by NodePort |
| LoadBalancer | If the cluster is running on a cloud provider, the service will be exposed through a load balancer created by the provider. |
| Ingress | The Serving Site that the Predictor specifies will create an Ingress rule that will route traffic to the service using the domain of the Serving Site. Depending if gRPC and/or REST Ingress is enabled on the Serving Site, the Predictor will have multiple paths to accept traffic for each. For example, if using the default-serving-site, the Predictor will be available locally at predictor-name.serving.vcap.me with gRPC, or predictors.serving.vcap.me/v1/predictors/predictor-name/ with REST. This option is recommended for exposing your Predictor externally and creating shareable links. For more information on how to create and manage an ingress, see this guide. |
The API exposed by the Predictor’s service is the GRPCInferenceService API. If the gRPC gateway is enabled, the Predictor will also expose the port one digit above the port specified by the Port field to accept REST requests and translate them to gRPC calls. The API provides a simple interface for sending predictions as a dictionary of the prediction’s features and their corresponding values as JSON or CSV. For more information on connecting to this service and serving live predictions, see this guide.
Add Model Deployments
The models that are accessible from the service are determined by the model deployment list. After creation, the Predictor will instantiate a prediction service for each consecutive model in the list if they do not already exist. To route predictions to individual models, the Predictor creates a proxy service with the name of the Predictor. Ensure that you are routing all requests to this service and not individual models to take advantage of MLOps features like prediction history.
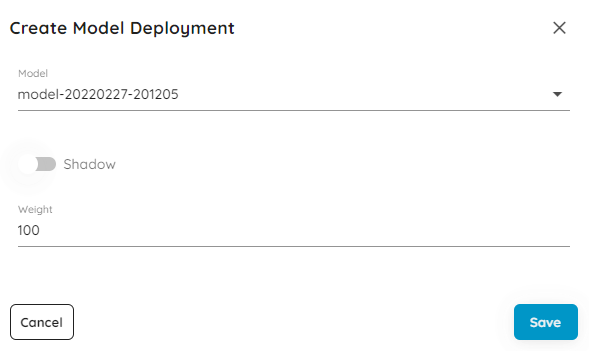
Note
The Shadow and Weight attributes of the model deployment are not functional in the current release.Confirm your selection and submit the resource to start the prediction service. Once the service is live, you can make test predictions through the Prediction tab of the Predictor specification.
Feedback
Was this page helpful?
Glad to hear it!
Sorry to hear that.